2. Data Models and Query Languages
Data models are perhaps the most important part of developing software. They shape not only how we write code, but how we think about the problem we’re solving. Most applications are built by layering data models: application objects map to database tables, which map to bytes in memory, which map to electrical currents. Each layer hides the complexity below it by providing a clean abstraction.
Relational Model vs Document Model
The relational model organizes data into relations (called tables in SQL), where each relation is an unordered collection of tuples (rows). Proposed by Edgar Codd in 1970, it became the dominant model for structured data:
- Transaction processing: Banking, airline reservations, stock trading
- Batch processing: Payroll, reporting, analytics
Relational databases generalized well beyond their original business data processing use case, and remained dominant for decades.
The Rise of NoSQL
NoSQL databases emerged in the 2010s with several driving forces:
- Scalability: Better handling of very large datasets or high write throughput than relational databases could offer
- Specialized queries: Support for operations not well-served by the relational model
- Schema flexibility: A more dynamic and expressive data model than rigid SQL schemas
- Open source: Preference for free software over commercial database products
The name “NoSQL” is somewhat of a misnomer—it’s better understood as “Not Only SQL.” Many applications now use a polyglot persistence approach, choosing the best tool for each use case.
The Object-Relational Mismatch
Most application code today is written in object-oriented languages. When data lives in relational tables, there’s an awkward translation layer between objects and rows/columns.
Impedance mismatch: The disconnect between the object-oriented programming model and the relational data model.
Object-relational mapping (ORM) frameworks like ActiveRecord and Hibernate reduce boilerplate, but can’t completely hide the differences.
One-to-Many Relationships
Consider a LinkedIn profile: one person has multiple jobs, multiple education entries, and multiple contact methods. In a relational database, this requires normalization—splitting the data across multiple tables linked by foreign keys:
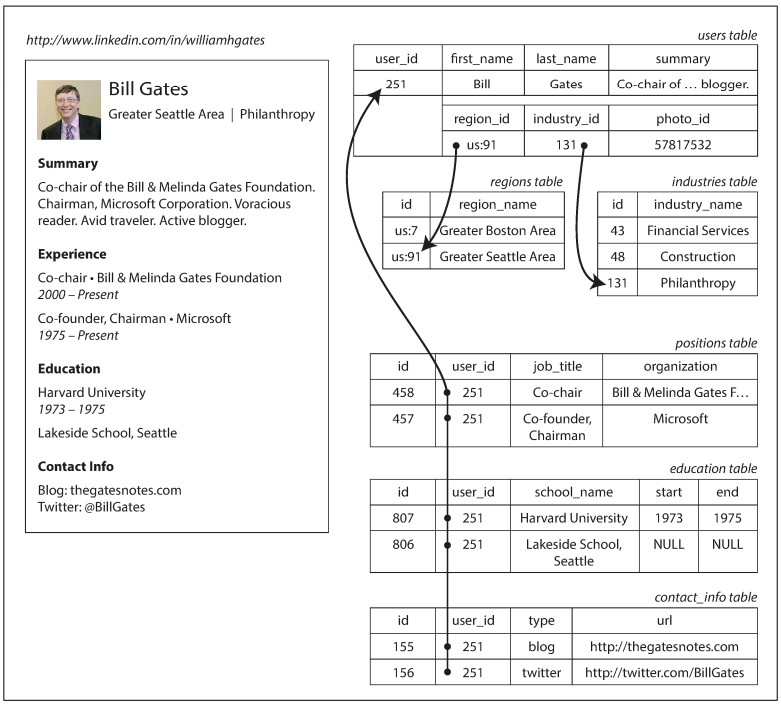
Document databases like MongoDB handle this more naturally. A JSON document can represent the entire profile in one place:
{
"user_id": 251,
"first_name": "Bill",
"last_name": "Gates",
"positions": [
{
"job_title": "Co-chair",
"organization": "Bill & Melinda Gates Foundation"
},
{
"job_title": "Co-founder",
"organization": "Microsoft"
}
],
"education": [
{
"school_name": "Harvard University",
"start": 1973,
"end": 1975
}
]
}
Data locality: Document models keep related information together, enabling retrieval with a single query rather than multiple joins.
Many-to-One and Many-to-Many Relationships
Document models excel at one-to-many relationships but struggle with many-to-one and many-to-many relationships. If multiple people work at the same organization, that organization should be stored once and referenced—but document databases don’t traditionally support joins.
This isn’t a new tension. The hierarchical model (IBM’s IMS, 1960s) also represented data as nested records and faced the same limitation.
The network model (CODASYL) generalized hierarchical data by allowing records to have multiple parents:
- Records were linked like pointers in a programming language
- Accessing data required traversing an access path from a root record
- Application developers had to manage these traversal algorithms manually, making the code fragile and difficult to change
The relational model solved this by letting the query optimizer choose the access path automatically—a key reason for its success.
Schema Flexibility
Schema-on-read: The structure of the data is implicit and only interpreted when data is read. (Document databases)
Schema-on-write: The schema is explicit and the database enforces that all data conforms to it. (Relational databases)
Schema-on-read is similar to dynamic typing in programming languages; schema-on-write is like static typing. Neither is universally better—the choice depends on the application.
Schema-on-read is advantageous when:
- Items in a collection don’t all have the same structure
- The structure is determined by external systems you don’t control
- The schema changes frequently
Convergence
The distinction between relational and document databases is blurring:
- Most relational databases now support JSON documents and XML
- Some document databases support relational-like joins (RethinkDB)
- MongoDB drivers can automatically resolve document references (client-side joins)
Graph-Like Data Models
When many-to-many relationships are common in your data, the graph model becomes natural. Graphs consist of vertices (nodes) and edges (relationships), and can model diverse data elegantly:
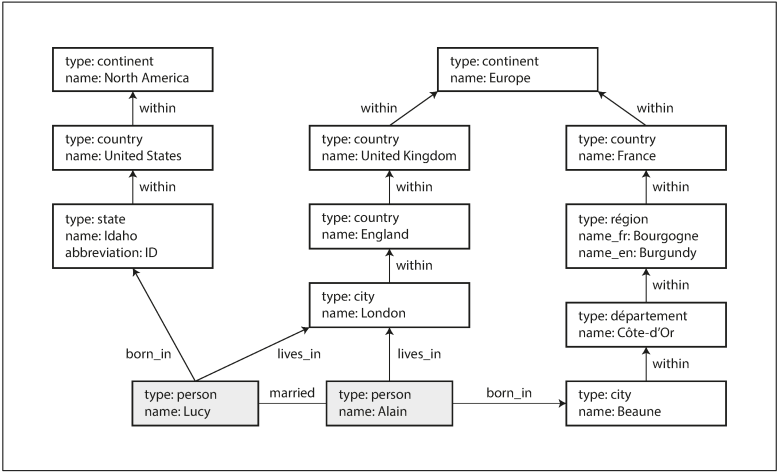
Graphs aren’t limited to homogeneous data. Facebook’s social graph includes people, locations, events, checkins, and comments—all as vertices with different types of edges connecting them.
Property Graphs
In the property graph model (used by Neo4j, Titan, InfiniteGraph), each vertex has:
- A unique identifier
- Outgoing edges
- Incoming edges
- Properties (key-value pairs)
Each edge has:
- A unique identifier
- Tail vertex (where the edge starts)
- Head vertex (where the edge ends)
- A label describing the relationship
- Properties (key-value pairs)
You could model this in a relational database with two tables (vertices and edges), but graph queries become unwieldy. Finding all vertices within two hops requires two joins; within three hops requires three joins. Since the number of joins isn’t known in advance, you’d need recursive SQL queries.
Cypher is a declarative query language designed for property graphs (created for Neo4j). Finding everyone who emigrated from the US to Europe:
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name
The WITHIN*0.. syntax elegantly handles variable-length paths through the location hierarchy.
Triple-Stores
The triple-store model represents all information as three-part statements: (subject, predicate, object).
- The subject is equivalent to a vertex
- The predicate and object are either:
- A property:
(lucy, age, 33)— Lucy is 33 years old - A relationship:
(lucy, marriedTo, alain)— Lucy is married to Alain
- A property:
Triple-stores are closely related to the semantic web vision of machine-readable data on the internet, though that vision hasn’t fully materialized.
SPARQL is the query language for triple-stores, with syntax inspired by Cypher (or perhaps it’s the other way around—SPARQL predates Cypher).