5. Replication
Replication means keeping a copy of the same data on multiple machines that are connected via a network. 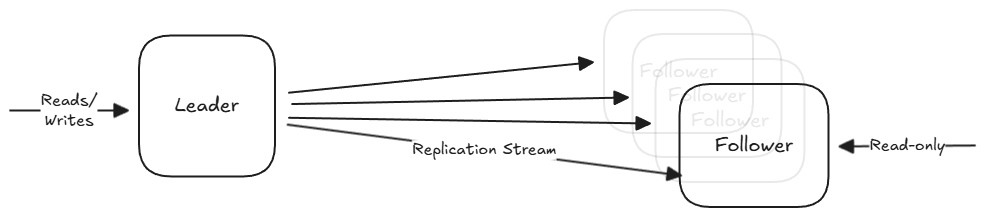 It comes with a number of benefits:
It comes with a number of benefits:
- Availability: Replication allows a system to continue function even if parts of it fail. When one machine fails, another can take over.
- Read throughput: For workloads that are “read-heavy”, we can scale the number of machines that serve queries (horizontal scaling), allowing us to distribute the read requests across those machines.
- Reducing latency: We can place copies of the data geographically closer to the users, reducing the time they spend waiting for network packets to travel to their location.
Single-Leader Partitioning
We start with several nodes that each store a copy of the database (replicas). These are split up into two categories:
- Leader (Master/Primary): The exclusive entry point for writes. When a client wants to change data, the request must go to the leader, which writes the change to its local storage first.
- Followers (Read Replicas/Slaves): Read-only nodes from the client’s perspective. They stay up to date by receiving a replication log from the leader. They apply every write in the same order that the leader processed them.
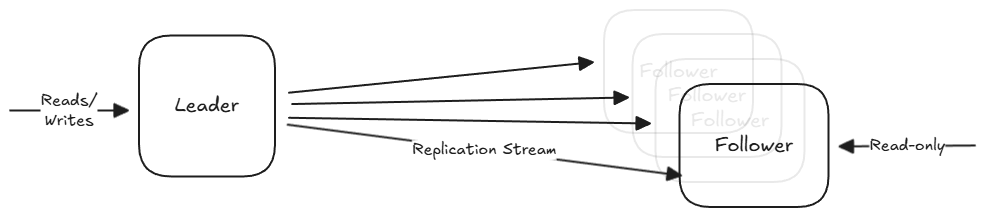
An important question to answer when designing the system is whether the replication stream should be synchronous and asynchronous.
- Synchronous Replication: The leader waits for the follower to confirm that it has received and written the data to its local storage before reporting success to the client.
- Pros: The follower is guaranteed to have an up-to-date copy of the data that is consistent with the leader. If the leader fails, you can be certain that the data exists on the follower.
- Cons: If the synchronous follower becomes unreachable (due to a crash or network fault), the leader cannot process any more writes. It must block until the replica is available again.
- In practice, people follow a semi-synchronous setup, where only one follower is synchronous while others remain asynchronous.
- Asynchronous Replication: The leader sends the data change message to its followers but notifies the client of success immediately without waiting for a response.
- Pros: High availability: The leader can continue processing writes even if all followers fall behind or the network is interrupted.
- Cons: Low durability: If the leader fails and cannot be recovered, any writes that were not yet replicated are lost forever.
Setting up new followers
Copying files from one node to another isn’t enough since writes are constantly happening. The actual process looks like this:
- Take a consistent snapshot of the leader’s database without locking the system.
- Move the snapshot to the new follower node.
- The new follower connects to the leader and requests all the data changes since the snapshot was taken. This requires the snapshot to be tied to a specific position in the replication log.
- Once the follower processes the backlog of changes, it has caught up and can continue receiving the live stream of data changes.
Node outages
If a follower goes down, it is relatively easy to fix.
- Followers keep a local log of all the changes it has received. So it knows the last transaction it sucessfully processed before the fault.
- When it restarts, it connects to the leader, requests the missing data since that point, and catches up.
If a leader fails, it is much more complex because the system must choose a new leader and redirect all traffic.
- Detection: Nodes ping each other; if the leader doesn’t respond for a period (often a 30-second timeout), it is assumed to be dead.
- A new leader is chosen, typically the replica with the most up-to-date data to minimize loss.
- Clients are updated to send writes to the new leader.
- If the old leader comes back, it is forced to be a follower.
This process is dangerous for a few reasons:
- In asynchronous setups, the new leader might not have received all the writes before the old leader died. The common solution is to discard those unreplicated writes.
- Split brain: Two nodes might both believe they are the leader. If both accept writes, data will be corrupted or lost.
- A timeout that’s too short can cause unnecessary failovers during temporary load spikes.
Replication Logs
There are several ways to format the replication log that the leader sends to its followers.
Statement-based Replication: The leader logs every write request (INSERT, UPDATE, DELETE) and sends them to the followers to execute.
- Pros: Very compact.
- Cons:
- Breaks with nondeterminism. Functions like
NOW()orRAND()will generate different values on each replica. - Autoincrementing columns (
UPDATE ... WHERE <some condition>) or statements with side effects (triggers, stored procedures) must be executed in the exact same order on every replica. This is difficult to guarantee with concurrent transactions.
- Breaks with nondeterminism. Functions like
Examples: MySQL (versions < 5.1).
Write-Ahead Log (WAL) Shipping: Every database uses a log for its storage engine (B-Trees or LSM-Trees). The leader sends this exact low-level log to its followers.
- Pros: Very efficient as it already uses the same log for crash recovery.
- Cons: The log is tightly coupled to the storage engine. If the database version changes its disk format, the leader and follower cannot run different versions of the software.
- It requires downtime for upgrades because you cannot perform rolling upgrades.
Examples: PostgreSQL, Oracle
Logical (row-based) Log Replication: It uses a sequence of records describing writes at the granularity of a row.
- For an inserted row: The log contains all new column values.
- For a deleted row: The log contains the primary key or enough info to identify the row.
- For an updated row: The log contains the identifier and the new values of the changed columns.
Benefits:
- Because it is “logical”, it will stay backward compatible. This makes it possible to do rolling upgrades.
- It is easier for external applications to parse.
Examples: MySQL
Trigger-based Replication: Useful when you need custom logic (like replicating a subset of data or between different types of DBs).
- Application-defined code automatically executes during a write transaction to log the change into a separate table. An external process can read this and replicate.
- This has significantly higher overhead and is more prone to bugs.
Examples: Databus for Oracle, Bucardo for Postgres
Dealing with Replication Lag
When you scale reads using asynchronous replication, you gain availability but lose strong consistency (in favor of eventual consistency).
While the replication lag is usually less than a second, it can spike to minutes under heavy load or network issues. This can lead to anomalies that require special handling.
Read-After-Write Consistency
Many applications allow users to submit data and then view it immediately. If the write goes to the leader but the subsequent read goes to a stale follower, the user will think the data is lost.
The guarantee that users can immediately see updates they submitted after reloading is called read-after-write consistency.
Some potential implementations:
- Leader-Routing: Always read a user’s own profile from the leader, but read other users’ profiles from a follower.
- Time-based Buffering: For one minute after the last update, make all reads from the leader.
- Timestamp Tracking: The client remembers the timestamp of its last write, and the system ensures that it only reads from a replica that is updated at least until that timestamp.
Monotonic Reads
An anomaly where a user sees things “moving backward in time”, because their requests are routed to different followers (with didfferent amounts of lag).
Sticky Routing: Ensure each user always reads from the same replica (e.g. hasing the user ID).
Consistent Prefix Reads
This guarantee says that if a sequence of writes happens in a certain order, then anyone reading those writes will see them in the same order.
This is a particular problem in sharded databases, since different partitions operate independently.
Causal Partitioning: Ensure that all writes that are causally related are written to the same partition.